In search of the best phone with the power of science!
Text analytics in e-commerce has become an extremely hot topic in the recent years. Linguistic processing of user-generated feedbacks helps companies to get actionable insights into customer preferences, concerns and demands. The insights enable you to provide best possible user experience, faster search in product catalogs, personalized product offers and recommendations, etc. All resulting in better conversions.
Besides, you can use these powerful analytics data to design products better tailored to real user needs.
A bright example of quickly evolving user demands and ongoing market disruption is the mobiles industry. It is still booming and very hi-tech, and it’s not enough to stay tuned to emerging trends, you have to stay ahead of these trends. This requires processing of huge amounts of user-generated content: reviews and feedbacks.
Reviews are difficult to analyze even for humans. Modern phones have dozens of different characteristics ranging from CPU and GPU vendor, clock speeds, amount of RAM and storage, battery capacity, etc. Many of these characteristics are related in non-obvious (for an average user) ways. For example, big battery capacity doesn’t necessarily mean that your device will hold up for a whole day if manufacturer equipped your device with huge bright screen and very powerful but not very power efficient processor. Another big issue is that some characteristics are only observable after long period of active usage in daily life. This creates a challenge for customers who are forced to rely on luck and buy product without sufficient knowledge about it. Or, they should google through the forums, online store pages with feedbacks and other information resources. Making an informed choice among different models can become a nightmare because there's so many characteristics and literally thousands of phone models available on the market.
All this makes customers very unhappy, because manual reading of many user reviews on internet is a very time consuming process. However, what if we can use some automatic way of sieving through piles of reviews to extract opinions on different products and do some analysis on top of it? In fact, there is a branch in machine learning called natural language processing (NLP). It’s focused on methods of automatic text understanding. This includes such tasks as document topic classification, syntactic analysis, named entity recognition and many others. But we are interested in a specific one called opinion mining. Opinion mining usually includes two steps.
Firstly, there is the identification of opinion targets and expressions that together form an entity called opinion. In our domain of interest, “target” is usually some aspect of a mobile phone like “battery”, “screen”, “cpu” and others and “expression” is usually an opinionated expression “is good”, “incredible”, “total junk” etc. Secondly, each opinion has a polarity that defines how the user treated the mentioned aspect, i.e. is it good or bad?
Let’s take the following sentence: “I think that battery life of this phone is awesome, but camera could be way better” as an example. This sentence contains two opinions: “battery life is awesome” and “camera could be way better”. The first opinion composed from “battery life” aspect and “is awesome” as an expression with positive polarity. The second opinion composed from “camera” as aspect and “could be way better” as an expression with negative polarity.
Of course, there can be additional steps and some kind of post-processing to link together all pieces of extracted information across different reviews texts.
Fortunately, here at Quiddi we already have a text analysis solution that is able to extract opinions from unstructured texts, identify their polarity and group them together. It is based on modern deep learning techniques such as recurrent neural networks, language models and sequence segmentation models.
So, let’s use the power of modern machine learning algorithms to create a data-driven comparison of mobile phones aspects.
We used an open Amazon review dataset as a base for our analysis. It contains reviews parsed from Amazon web store, ranging from year 1999 through 2015. The data seems a bit outdated, but it suits our purpose.
We ran our opinion mining algorithm against this dataset to extract all opinions with their sentiments so now we can analyse these opinions in any way we want.
First of all, if we want to compare different phones, we should define the set of essential characteristics that we want to compare. One way to do it is to think thoroughly and write them down one by one. However, as we have access to the data, why don’t we try and find the aspects that are bothering users the most? We can aggregate opinions by aspect and count their mentions in the reviews.
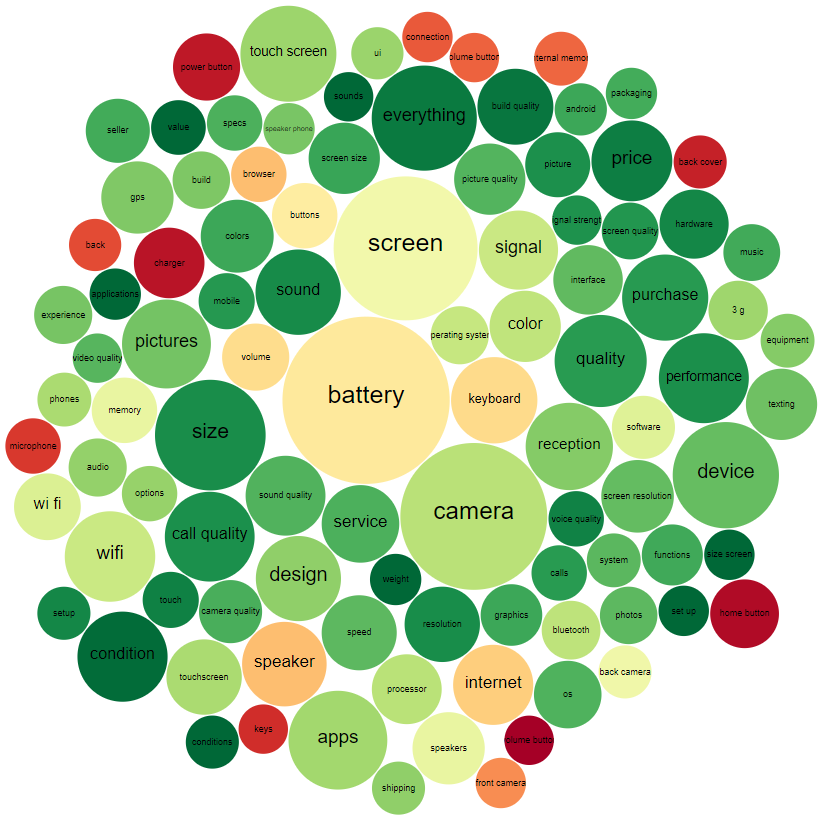
As you can see, the N most popular aspects are these: battery, screen, camera, performance and so on. It is interesting that users have very positive thoughts about almost all aspects besides physical parts of the phone like “volume button”, “home button”, power button“ and phone accessories.
Now when we have a list with the most popular aspects and we can use this list to make a comparison of different phones. This is fairly simple: we calculate mean opinion sentiment for each aspect in the list for each phone.